1. Download the virtual machine
For this laboratory, we will not use python, but FUGE.
This version of FUGE runs only on Linux. We recommend that you use the LFA_VM_2016 Virtual Machine.
2. Test FUGE
- Open a terminal in the FUGE_with_data directory
- Type ./run.sh to start FUGE. The main window should open.
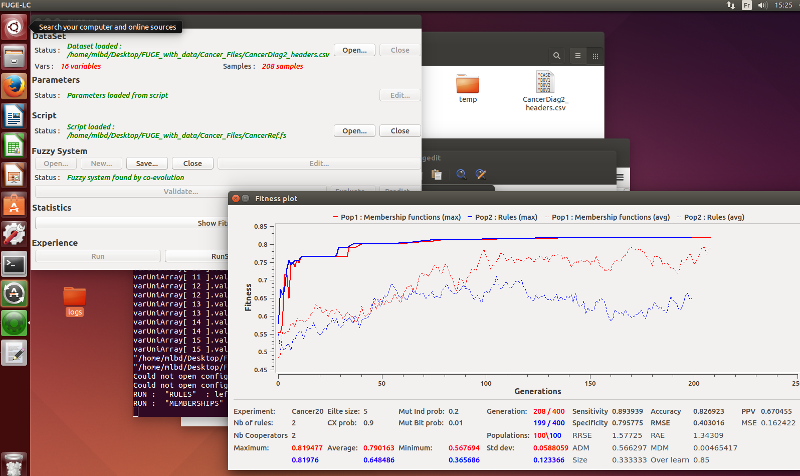
- Load the Cancer_Files/CancerDiag2_headers.csv dataset by using the "Open..." button of the Dataset section of the main window.
- Open the Cancer_Files/CancerRef.fs script using a text editor. Verify that savePath points to an existing directory (e.g. /home/lfa/Desktop/test). This is the path where FUGE will save its log files.
- Load the script in FUGE using the "Open..." button of the Script section.
- Click the "Show Fitness Plot" button
- Start the coevolution with "RunScript"
- You should see a plot with the performance of the system. After some time, you will also see some log folders appear on the destination you chose (fuzzySystems, logs)
3. Assignment - Supervised Learning, Evolution of fuzzy systems

|
Those who predict, don't have knowledge." Lao Tzu, 6th Century BC |
In this laboratory you will explore another approach to supervised learning. The goal of this practice is to build a simple rule-based model able to both detecting the presence of arrhythmia in an electrocardiogram and explaining the conditions allowing to such diagnostic. To do that you will apply a method based on evolutionary fuzzy modelling, that combines the knowledge representation of fuzzy logic with the search power of artificial evolution.
1. Fuzzy Systems and Fuzzy Modeling
A fuzzy inference system (or simply a fuzzy system) is a rule-based system that uses fuzzy logic, rather than Boolean logic, to reason about data. Fuzzy logic is a computational paradigm that provides a mathematical tool for representing and manipulating information in a way that resembles human communication and reasoning processes. It is based on the assumption that, in contrast to Boolean logic, a statement can be partially true (or false), and composed of imprecise concepts. For example, the expression "I live near Geneva", where the fuzzy value "near" applied to the fuzzy variable "distance", in addition to being imprecise, is subject to interpretation. The foundations of Fuzzy Logic were established in 1965 by Lotfi Zadeh in his seminal paper about fuzzy sets. Fuzzy models present three distinguishable features: (1) the use of linguistic variables in place or in addition to numerical variables, (2) the description of simple relations between variables by conditional fuzzy statements, and (3) the characterization of complex relations by fuzzy algorithms. An important issue in designing fuzzy models, which is a difficult and extremely ill-defined process, involves the question of providing a methodology for their development. i.e., a set of techniques for obtaining the fuzzy model from information and knowledge about the system.
Fuzzy modeling is thus the task of identifying (finding, discovering, computing) the parameters of a fuzzy inference system so that a desired behavior is attained. Note that, due to linguistic and numeric requirements, the fuzzy-modeling process has generally to deal with an important trade-off between the performance and the interpretability of the model. In other words, the model is expected to provide high numeric precision while incurring as little a loss of linguistic descriptive power as possible. One of the major problems in fuzzy modeling is the curse of dimensionality, meaning that the computation requirements grow exponentially with the number of variables.
2. Evolutionary Computation and Evolutionary Fuzzy Modeling
The domain of evolutionary computation involves the study of the foundations and the applications of computational techniques based on the principles of natural evolution. Evolution in nature is responsible for the "design" of all living beings on earth, and for the strategies they use to interact with each other. Evolutionary algorithms employ this powerful design philosophy to find solutions to hard problems. They are used to search large, and often complex, search spaces and have proven worthwhile on numerous diverse problems, able to find near-optimal solutions given an adequate performance (fitness) measure.
Fuzzy modeling can be considered as an optimization process where part or all of the parameters of a fuzzy system constitute the search space. Inviting, thus, to use evolutionary algorithms to drive such a process. Depending on several criteria, including the available a priori knowledge about the system, the size of the parameter set, and the availability and completeness of input-output data, artificial evolution can be applied in different stages of the fuzzy-parameter search. In many cases, the available information about the system is composed almost exclusively of input-output data. In such a case, evolution has to deal with the simultaneous design of rules and membership functions.
In our group we apply a Cooperative Coevolutionary approach to fuzzy modeling wherein two coevolving species are defined: one for evolving membership functions and a second one for evolving rules. Under this approach, the fuzzy modeling problem is solved by two coevolving, cooperating species. Individuals of the first species encode values which define completely the membership functions for all the variables of the system. Individuals of the second species define a set of rules of the form:
where the term Ai indicates which one of the linguistic labels of the fuzzy variable V is used by the rule. For example, a valid rule could contain the expression:
which includes the membership function Warm whose defining parameters are contained in the first species.
3. Evolution of Fuzzy Systems with FUGE
In this laboratory session you will use the tool FUGE (standing for FUzzy Genetic Engine) conceived and maintained at the HEIG-VD by Professor Peña's team. (You should add the current version of FUGE to your virtual machine following the instructions received separately.) For the purpose of this laboratory you will use the tool through its main user interface (shown in the figure below), although the tool allows for more automated execution based on either a simple script utility or by means of command line calls.
- Increasing the weight of the Size criterion (e.g., use for example 0.9 or 1 as weight)
- Searching explicitely for systems with 2 rules, 2 variables per rule, and 2 membership functions per variable.
- How do these systems perform, in terms of specificity, sensitivity, and accuracy, as compared with your previous experiments?
- How do these small systems compare with your best system in terms of linguistic simplicity?
- Are them more "interpretable"?"
Good luck!!
Report deadline: 05.05.2016
Please, provide a brief report describing your experiments and the results you obtained using the provided data. You should preferably work in groups of two.
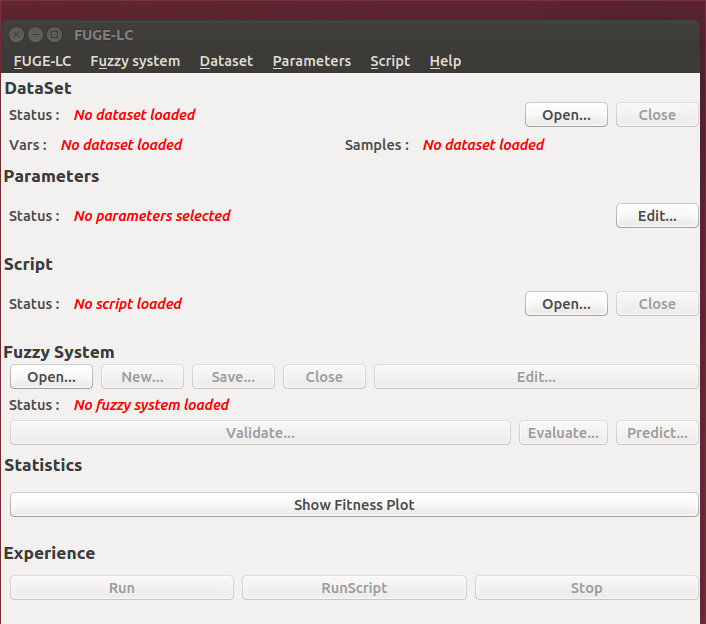
Figure 1. FUGE Main Window.
3.1. An Introductory Example
In this example we are going to use a very popular dataset concerning the classification of Iris flowers. This is, perhaps, the best known database to be found in the pattern recognition literature. The data set consists of 50 samples from each of three species of Iris (Iris setosa, Iris virginica and Iris versicolor). One class is linearly separable from the other 2; the latter are not linearly separable from each other. The data we are going to use as explanatory variables (inputs) are the measurements in centimeters of the sepal length and width and petal length and width. The output variable, on the other hand, is the species of Iris: setosa, versicolor and virginica.
This dataset is contained within the corresponding directory and may be accessed through the Open... button in the Dataset section. Figure 1 shows a scatterplot of the Iris dataset. Notice that, as mentioned, one of the classes is linearly separable from the others (i.e., setosa in red).

Figure 2. Iris Data Scatterplot.
Once, the dataset is loaded, you should define the parameters of the algorithm. This is done through the Edit... button in the Parameters section which open a dialog window already containing default parameter values. It is possible to load/save these values from/in a configuration file (extension .config). You will find such a file into the provided Iris data directory contaning the parameters shown in Figure 3.
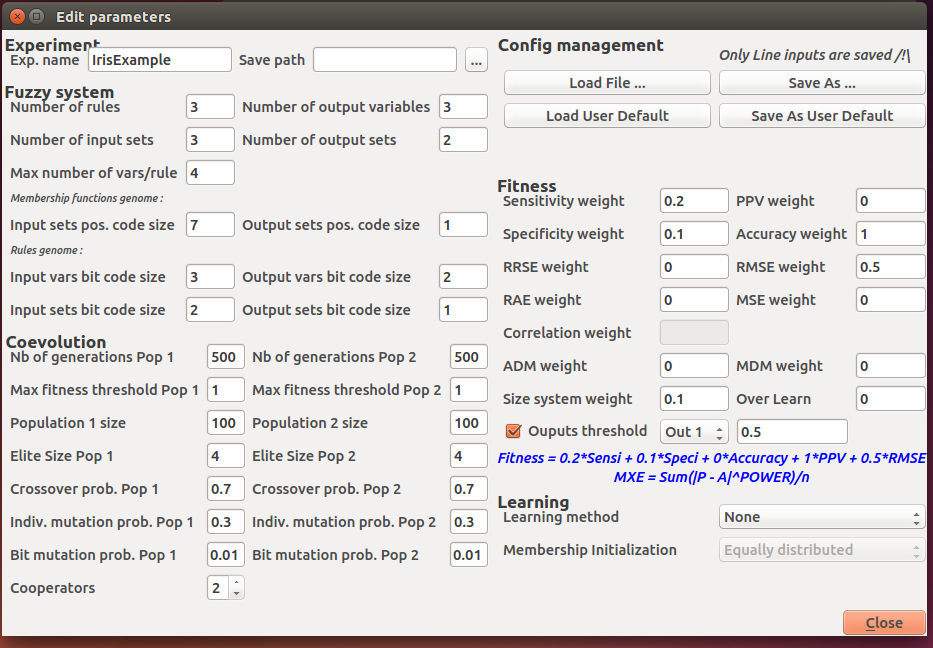
Figure 3. Parameter setting for the Iris dataset.
Some modifications must be done to these parameters so as to correctly create a model for a given problem using FUGE. You are allowed to modify all the parameters to improve the behaviour of the algorithm and to obtain better results. For example, increasing the number of generations will cause coevolution to run longer and hence, to further explore the space of solutions (fuzzy systems).
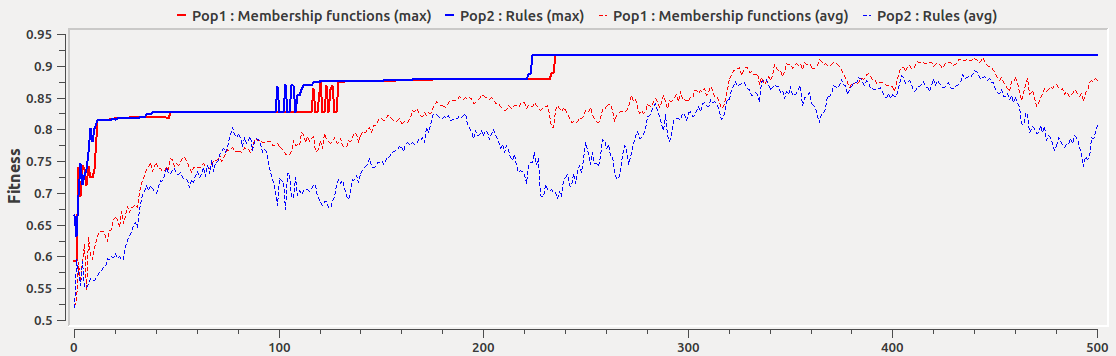
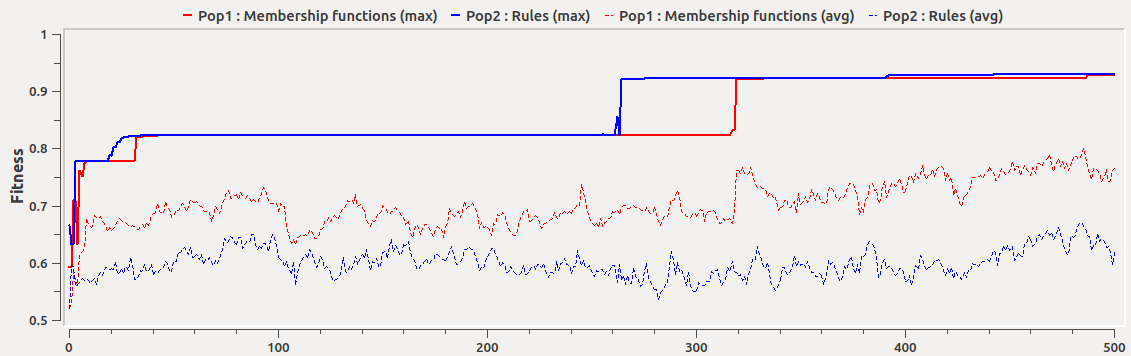
Once the parameters have been set either directly or through a script, the experience can be launched with the button Run. The behaviour of the ongoing evolutionary run may be monitored through the Fitness Plot window as illustrated in Figure 4. As it can be observed, it is important to allow coevolution to run long enough. In this particular example, if we stopped the evolution at 100 generations we would miss a further tuning of the models happening later (red oval).
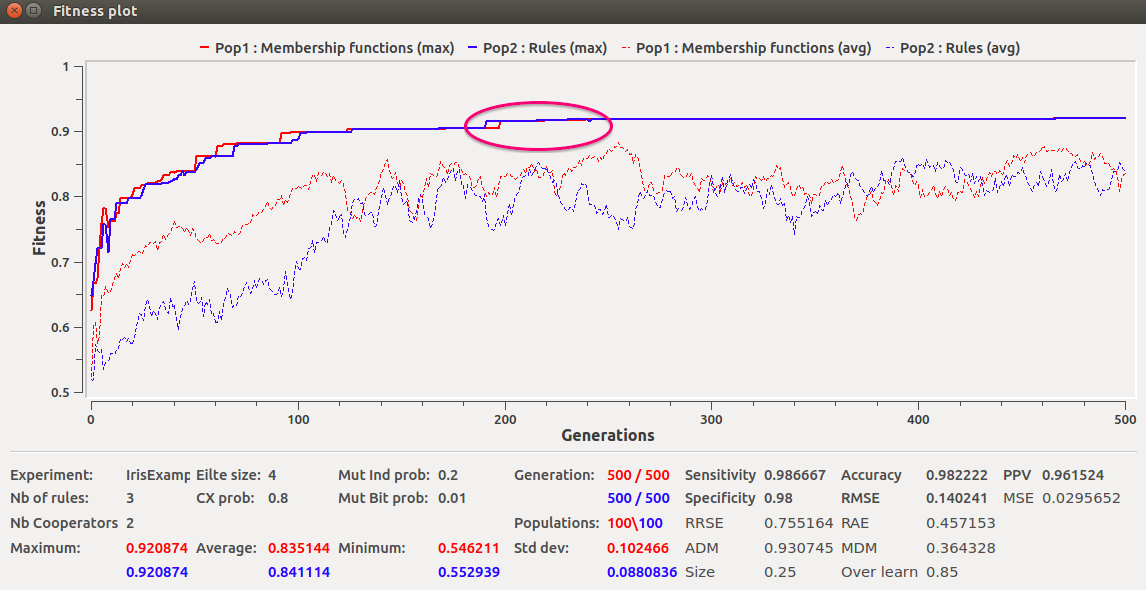
Figure 4. Fitness evolution through an experiment running 500 generations.
Depending on the problem, you may want, or need, to change the size of the population, the crossover rate, the mutation rate, the number of rules, the number of variables per rule, or any of the parameters listed in Figure 3. FUGE provides a basic scripting capability that facilitates programming a series of experiments with varying parameter values. These scripts are managed through the commands avaiable in the Script section, and its execution launched with the RunScript button.
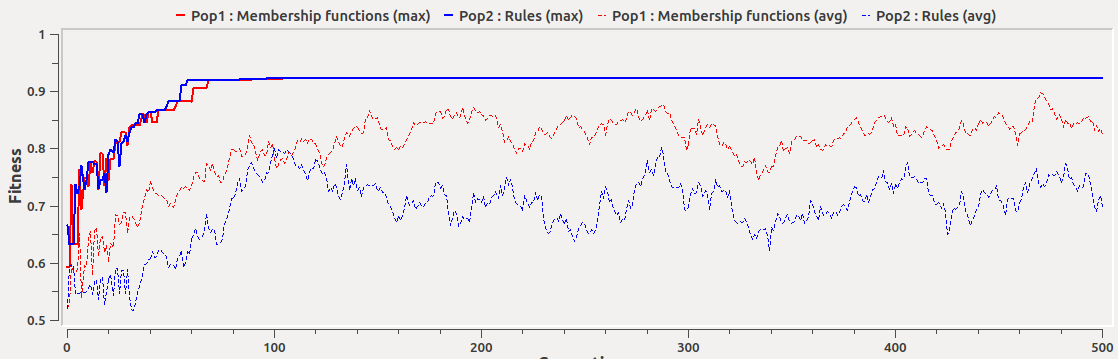
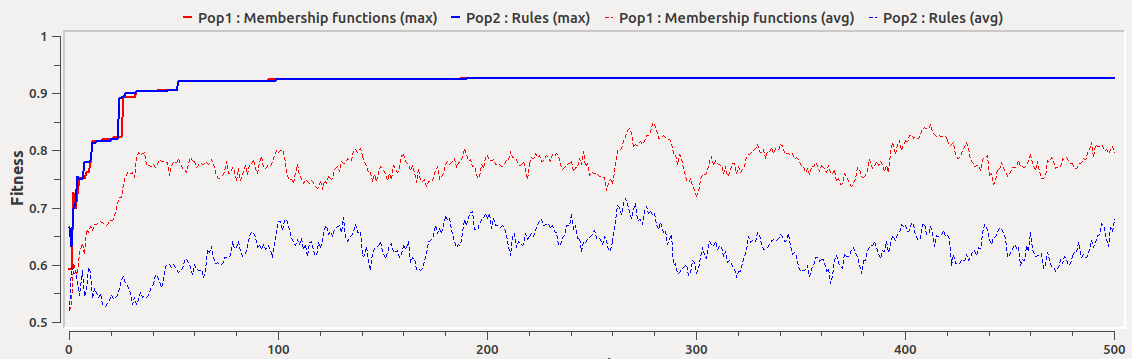
For instance, changing the individual mutation rate will influence the amount of "novelty" of the population and thus its capacity to carefully explore a given area in the solution space. The example shown by Figure 4 illustrates the effects on the fitness of different mutation rates. As it can be seen, higher mutation rates decrease the average fitness, which means that the search for better solutions is guided more by chance than by the evolutionary operators (i.e., selection and crossover). Notice that due to the simplicity of the Iris dataset, the mutation rate seems to have little effect on the best systems found. However, it may be deleterous in other harder modelling problems.
|
|
| |
|
|
|
| |
|
As you may have noticed, the best system found by FUGE can be saved after the evolutionary run (in a script execution it is done after each experiment). The file (with extension .ffs in XML format) contains a description of the system as well as information on the weights of the different criteria used to compute its fitness. These files are managed through the Fuzzy System section.
Saved systems may be reloaded on FUGE with the Open command and their behaviour on a given dataset simulated with the Validate and Evaluate commands. (Note: The Validate command is usually used on the system obtained from an ongoing experiment to validate its behaviour on the training dataset used to evolve it. The Evaluate command is used on any fuzzy system with any compatible dataset, including test sets). Figure 6 shows the evaluation of an example evolved model for the Iris dataset.
As one can notice, the window offers also additional information on the rules and membership functions of the systems as well as on its performance measurements (fitness). In the example, the model possesses two rules that use only two of the four input variables (i.e., PL and PW). It attains an accuracy of 97.33%, corresponding to 96% of sensitivity and 98% of specificity.
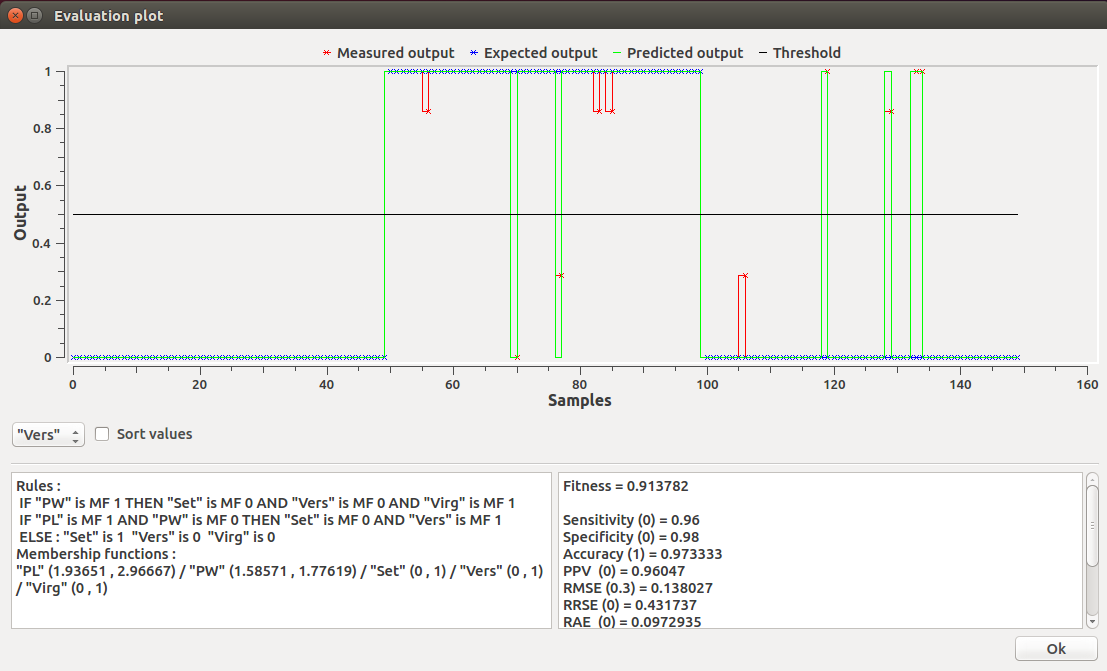
Figure 6. Evaluation of an evolved Iris model. The graphic illustrates the system's behaviour for the second output variable Versicolor. Two additional windows show a summary of the fuzzy system under evaluation and of its fitness evaluation.
All the details of the current fuzzy system may be revised and modified through the Edit command. In this context it is also possible to obtain a graphic representation of the membership functions to better understand them. Figure 7 shows the membership functions of the two variables used by the fuzzy system under analysis.
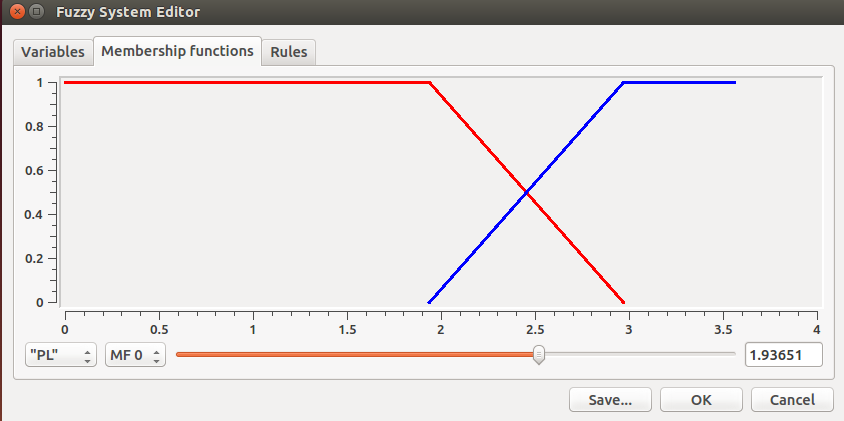 | 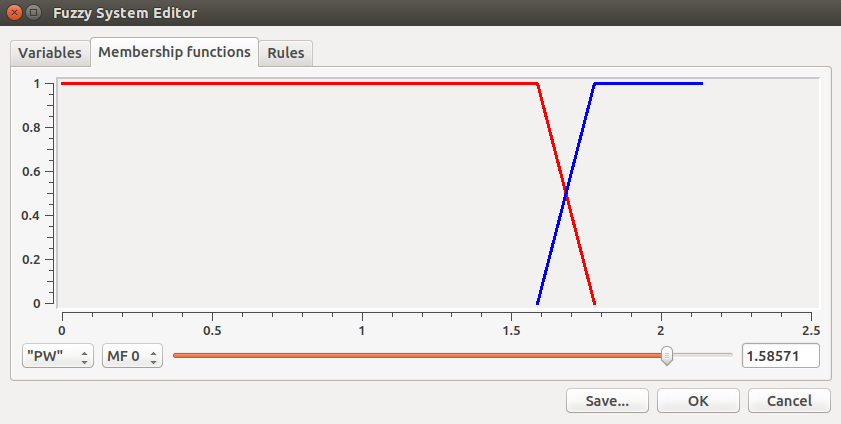 |
4. Evolution of a classifier based on fuzzy systems for the detection of arrhythmia
4.1 The dataset
The arrhythmia dataset contains relevant information for detecting arrhythmia in 452 subjects. There are 279 input attributes (or features) and one class attribute indicating whether the observation was taken from a person suffering arrhythmia or not. More information about this dataset can be found on the UCI machine learning repository. The original dataset containing information about 16 different types of arrhythmia has been simplified to a simpler diagnostic: normal or arrhythmia. The simplified dataset is available in the corresponding data directory.
|
4.2 Exercise
You have to build arrhythmia detectors using the evolutionary approach presented above for building fuzzy systems. The script included in the data directory gives you a starting point. To allow evolution building good fuzzy classifiers, you have to modify this script and find adequate parameter values, i.e., number of generations, population size, mutation rate, number of membership functions per input, number of rules, number of variables per rule. Bear in mind that small systems are easier to interpret, and perhaps easier to discover, than larger ones (Although they possibly attain lower performances). Once you have found an adequate set of parameter values, report your results (obtained through several tests) using three different combination of weights for the fitness function, as follows:
Look at the differences in accuracy, sensitivity and specificity obtained in all cases. Analyse two or three of the best systems you obtained. Look at their rules, their input variables and their membership functions. Is it possible/easy to interpret these systems? (Note: A brief description of the input variables can be found in the UCI machine learning repository). Try now to obtain some smaller fuzzy systems. To obtain them you should use two approaches: Analyze the best systems obtained in both cases and answer the following questions about them: |
April 2016